简介
之前的模型(seq2sql,sqlnet)完全忽略了各个column的数据类型,但数据类型其实是一个很重要的信息,比如在预测WHERE子句时,只有数值类型的column才可以比较大小,字符...
分类标签归档:自然语言处理
之前的模型(seq2sql,sqlnet)完全忽略了各个column的数据类型,但数据类型其实是一个很重要的信息,比如在预测WHERE子句时,只有数值类型的column才可以比较大小,字符...
SQLNet模型是紧随WIkiSQL数据集之后的一个比较知名的Baseline。由于WikiSQL数据集中的SQL比较简单,如下图所示为一个WIkiSQL中的示例,因而SQLNet将预测一...
import torch
from torch import nn
import numpy as np
class ScaledDotProductAttention(nn.Module)...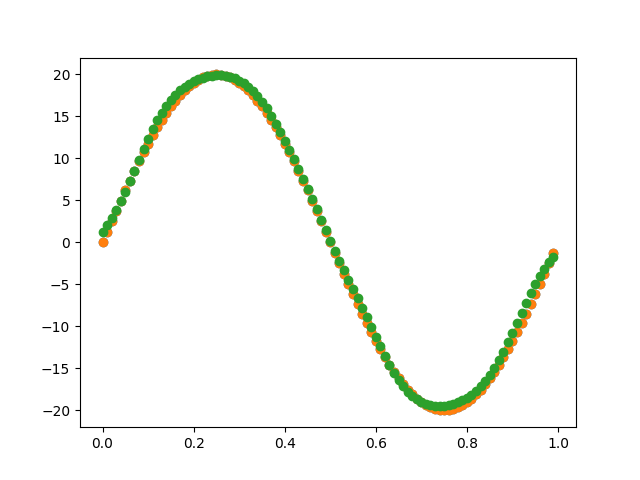
import numpy as np
from matplotlib import pyplot as plt
# 生成权重以及偏执项layers_dim代表每层的神经元个数,
# 比如[...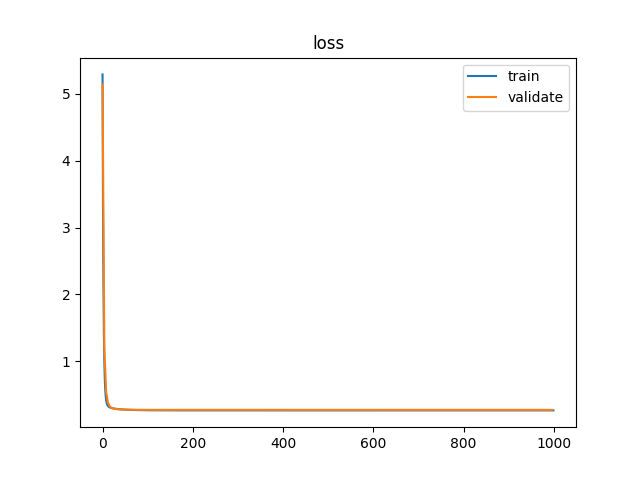
# 数据加载
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import...1、训练神经网络时如何确定batch的大小?
(1)GPU对2的幂次的patch可以发挥更佳的性能,因此设置成16、32、64、128.时往往要比设置为整10、整100的倍数时表现更优
(2)b...
所有数据集均来源于网络,只做整理供大家提取方便,如果有侵权等问题,请及时联系我们删除。
** 需要以下数据,可以评论区留言**